本文总阅读量
golang基础教程
第一章 fmt包
fmt包中常见的方法:
fmt.Println("a"):表示换行输出
1
2
fmt . Print ( "b" , "c" )
fmt . Print ( "a" )
以上代码不会换行输出:bca
1
2
3
a := 10
fmt . Printf ( "a的值为 %v" , a ) // 表示格式化输出,%v相当于占位符,输出a的值
//输出 a的值为 10
%T:判断一个变量的类型
%d:值以10进制输出
变量的声明
var关键字
1
var a int = 10 //int 可以省略
类型推导方式
go会自动根据右边值的类型来推导
变量的初始化
Go 语言在声明变量的时候,会自动对变量对应的内存区域进行初始化操作。每个变量会被
初始化成其类型的默认值,例如: 整型和浮点型变量的默认值为 0。 字符串变量的默认值
为空字符串。 布尔型变量默认为 false。 切片、函数、指针变量的默认为 nil。
声明一个string类型的变量并打印
1
2
var username string
fmt . Println ( username ) //输出为空
1
2
var age int
fmt . Println ( age ) //输出为0
匿名变量
在使用多重赋值时,如果想要忽略某个值,可以使用匿名变量 (anonymous variable)。 匿
名变量用一个下划线 _ 表示
1
2
3
4
5
6
7
8
func getUserinfo () ( int , string ) {
return 10 , "张三"
}
func main (){
age , _ := getUserinfo () // 用_ 忽略返回的 "张三"
fmt . Println ( age )
}
常量
常量用const命名,常量定义的时候必须马上赋值,常量定义后不能被修改。
1
2
const pi = math . Pi
fmt . Printf ( "%v %T" , pi , pi ) // 3.141592653589793 float64
iota
iota 是 golang 语言的常量计数器,只能在常量的表达式中使用。
iota 在 const 关键字出现时将被重置为 0(const 内部的第一行之前),const 中每新增一行常量
声明将使 iota 计数一次(iota 可理解为 const 语句块中的行索引)。
1
2
3
4
5
const (
a = iota //const 第一次出现时iota为0
b = iota // const 第二次为1 可以理解为const语句的行索引
)
fmt . Println ( a , b ) // 0 1
iota使用_跳过某些值
1
2
3
4
5
6
7
8
9
const (
a = iota
_
b
_
c
)
fmt . Println ( a , b , c ) //0 2 4
}
列子:定义b kb,mb,gb,tb,pb常量
1
2
3
4
5
6
7
8
9
10
const (
b = 1 << ( 10 * iota )
kb // 1<<10 0000 0000 0001 0100 0000 0000
mb
gb
tb
pb
)
fmt . Println ( b , kb , mb , gb , tb , pb )
//1 1024 1048576 1073741824 1099511627776 1125899906842624
第二章 golang的基本数据类型
1.go数据类型介绍
go语言中数据类型分为:基本数据类型和复合数据类型
基本数据类型:
整数型,浮点型,布尔型和字符串
复合数据类型:
数组,切片,结构体,函数,map,通道和接口等
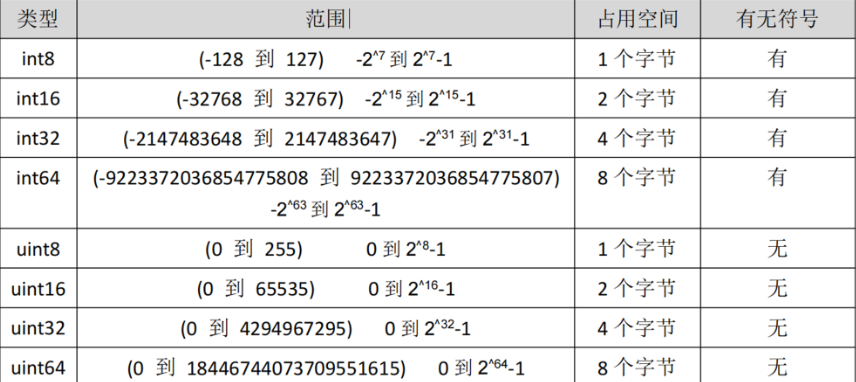
2.整型
整型分为以下两个大类:
有符号整形按长度分为:int8、int16、int32、int64
对应的无符号整型:uint8、uint16、uint32、uint64
每个类型的取值范围是不一样的
1
2
var num int8 = 150
fmt . Println ( num ) //报错 因为num是int8,取值只能在-128和127之间
关于字节:
字节也叫 Byte,是计算机数据的基本存储单位。8bit(位)=1Byte(字节) 1024Byte(字节)=1KB
1024KB=1MB 1024MB=1GB 1024GB=1TB 。在电脑里一个中文字是占两个字节的。
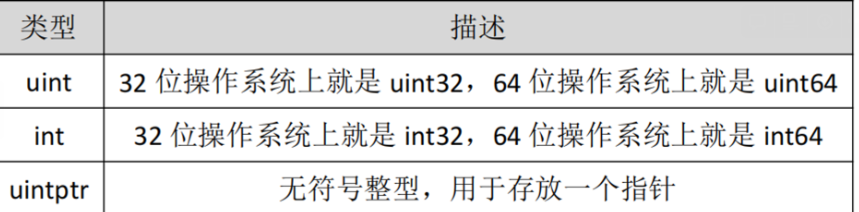
特殊整型
注意: 在使用 int 和 uint 类型时,不能假定它是 32 位或 64 位的整型,而是考虑 int 和 uint
可能在不同平台上的差异。
**注意事项:**实际项目中整数类型、切片、 map 的元素数量等都可以用 int 来表示。在涉及
到二进制传输、为了保持文件的结构不会受到不同编译目标平台字节长度的影响,不要使
用 int 和 uint。
unsafe.Sizeof
函数可以得出一个变量在内存中的存储空间是几个字节。
int 不同长度直接的转换
低位可以任意转换为高位,但是高位转为低位时要注意高位的数据取值会不会转换的时候超出低位的取值范围和溢出。
数字字面量语法(Number literals syntax)(了解)
Go1.13 版本之后引入了数字字面量语法,这样便于开发者以二进制、八进制或十六进制浮
点数的格式定义数字,例如
v := 0b00101101, 代表二进制的 101101,相当于十进制的 45。 v := 0o377,代表八进制的
377,相当于十进制的 255。 v := 0x1p-2,代表十六进制的 1 除以 2²,也就是 0.25。 而
且还允许我们用 _ 来分隔数字,比如说:
v := 123_456 等于 123456。
我们可以借助 fmt 函数来将一个整数以不同进制形式展示。
%v:原样输出
%d: 以十进制输出
%b: 以二进制输出
%o: 以8进制输出
%x: 以16进制输出
%c: 以字符输出
浮点型
%.2f:表示保留2位小数输出
%f:表示默认保留6位小数输出
%.4f: 表示保留4位小数
Go 语言中浮点数默认是 float64 64位系统中默认浮点是float64
1
2
3
f1 := 3.1415
fmt . Printf ( "%v 类型是%T" , f1 , f1 )
// 3.1415 类型是float64
科学计数法表示浮点型
1
2
3
f1 := 3.14e2 // 3.14*10的2次方 f1 := 3.14e-2 3.14/10的2次方
fmt . Printf ( "%v 类型是%T" , f1 , f1 )
// 314 类型是float64
Go语言中的精度丢失
几乎所有的编程语言都有精度丢失这个问题,这是典型的二进制浮点数精度损失问题,在定
长条件下,二进制小数和十进制小数互转可能有精度丢失。
1
2
3
4
f1 := 8.2
f2 := 3.8
fmt . Println ( f1 - f2 )
// 4.3999999999999995
利用第三方包解决
https://github.com/shopspring/decimal
1
2
3
4
f1 := 8.2
f2 := 3.8
f3 := decimal . NewFromFloat ( f1 ). Sub ( decimal . NewFromFloat ( f2 ))
fmt . Println ( f3 ) // 4.4
4、布尔值
Go 语言中以 bool 类型进行声明布尔型数据,布尔型数据只有 true(真)和 false(假)两个
值。
注意:
布尔类型变量的默认值为 false。
Go 语言中不允许将整型强制转换为布尔型.
布尔型无法参与数值运算,也无法与其他类型进行转换。
字符串
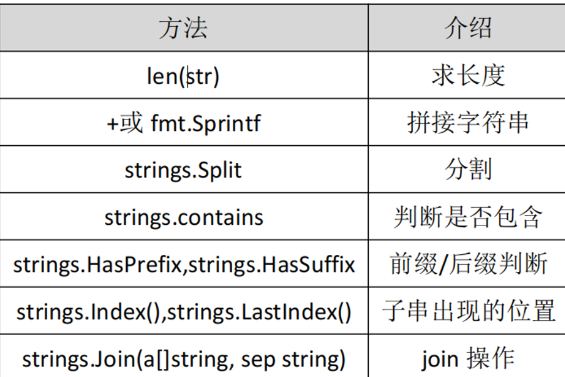
字符串的常用操作
1
2
str := "你好"
fmt . Println ( len ( str )) //输出6 因为一个汉字代表3个字节
1
2
3
4
5
//拼接字符串 "+"
str1 := "你好"
str2 := "golang"
str3 := str1 + str2
fmt . Println ( str3 ) // 你好golang
1
2
3
4
5
//使用 fmt.Sprintf 拼接
str1 := "你好"
str2 := "golang"
str3 := fmt . Sprintf ( "%v %v" , str1 , str2 )
fmt . Println ( str3 )
1
2
3
str := "golang,javascript,c,c++"
str2 := strings . Split ( str , "n" )
fmt . Printf ( "%v %T" , str2 , str2 ) //[gola g,javascript,c,c++] []string
string.Join():把切片转为字符串
1
2
3
sliceA := [] string { "c++" , "golang" , "java" , "javascript" }
str := strings . Join ( sliceA , "," )
fmt . Println ( str ) //c++,golang,java,javascript
strings.Index():查找字符串是否包含另一个字符串,如果有返回下标,没有返回-1
1
2
3
str := "hello golang"
index := strings . Index ( str , "go" )
fmt . Println ( index ) // 6
strings.Lastindex():查找子字符串最后出现的位置,没有返回-1
1
2
3
str := "hello go golang"
index := strings . LastIndex ( str , "go" )
fmt . Println ( index ) //9
byte 和 rune 类型
组成每个字符串的元素叫做“字符”,可以通过遍历字符串元素获得字符。 字符用单引号 ‘ ’
包裹起来。
一个字母占用一个字节(对应的值为ascii编码的值),一个汉字占用3个字节(对应utf-8编码的值)。
1
2
a := 'a'
fmt . Printf ( "%v %c" , a , a ) // 97 a 97是输出的ASCII码 a是字符输出
go语言的byte类型其实就是int8,代表一个ASCII的字符
rune类型,代表一个UTF-8字符,它实际上是一个int32类型
💡 要想循环带汉字的字符串需要用range不能用for
修改字符串中的字符
要修改字符串,需要先将其转换成[]rune 或[]byte,完成后再转换为 string。无论哪种转换,
都会重新分配内存,并复制字节数组。
1
2
3
4
a := "abc"
strSlice := [] byte ( a )
fmt . Println ( strSlice ) // 输出是以字符串abc的byte(int8)切片
// [97 98 99]
1
2
3
4
5
a := "abc"
strSlice := [] byte ( a )
strSlice [ 0 ] = 'd'
fmt . Println ( string ( strSlice )) //输出 dbc
fmt . Println ( a ) // 输出abc
第三章 基本数据类型的转换
转换的时候建议从低位转换成高位,高位转换成低位的时候如果转换不成功就会溢出,和我
们想的结果不一样。
如 int类型转为float,int8转为int16,如果把高位转为低位有可能会溢出(overflow)
把其他类型转为string类型
方法一: 使用fmt.Sprintf()
%d:整型转为string类型
%f:浮点转为string类型 (%.2f:表示保留两位小数)
%t :布尔转为string类型
%c: 字符型转为string类型
方法二:利用strconv包的方法
strconv.FormatInt():将int转为string类型
strconv.FormatFloat():将float转为string类型
1
2
3
f := 25.868686
str := strconv . FormatFloat ( float64 ( f ), 'f' , 10 , 64 )
fmt . Println ( str ) //25.8686860000
第四章 数组
数组是指一系列同一类型数据的集合。数组中包含的每个数据被称为数组元素
(element),这种类型可以是任意的原始类型,比如 int、string 等,也可以是用户自定义的
类型。一个数组包含的元素个数被称为数组的长度。在 Golang 中数组是一个长度固定的数
据类型,数组的长度是类型的一部分 ,也就是说 [5]int 和 [10]int 是两个不同的类型。Golang
中数组的另一个特点是占用内存的连续性,也就是说数组中的元素是被分配到连续的内存地
址中的,因而索引数组元素的速度非常快。
和数组对应的类型是 Slice(切片),Slice 是可以增长和收缩的动态序列,功能也更灵
活,但是想要理解 slice 工作原理的话需要先理解数组,所以本节主要为大家讲解数组的使
用。
数组的初始化
var 数组名 元素数量 数组类型
数组初始化时候不指定长度,用[…]表示让编译器根据初始值的个数自行推断数组的长度
1
var city = [ ... ] string { "北京" , "上海" , "广东" , "深圳" }
数组的遍历
for循环或者for range
1
2
3
4
5
6
7
var arry = [ ... ] string { "上海" , "北京" , "广州" , "深圳" }
for i := 0 ; i < len ( arry ); i ++ {
fmt . Println ( arry [ i ])
}
for _ , v := range arry {
fmt . Println ( v )
}
数组是值类型
值类型:在golang中基本数据类型和数组,结构体都是值类型,值类型在赋值和函数传参的时候都是拷贝复制。
引用类型:赋值和函数传参的时候,是传递的指向值的指针或者叫引用,指向了同一个内存空间。
所以改变引用类型的副本会改变本身的值。
值类型:
1
2
3
4
5
6
7
a := 10
b := a // 赋值操作的时候相当于拷贝了一份a给b
a = 30
fmt . Println ( a )
fmt . Println ( b )
// 30
// 10
引用类型:
1
2
3
4
5
6
7
sliceA := [] int { 1 , 2 , 3 }
sliceB := sliceA
sliceA [ 0 ] = 22
fmt . Println ( sliceA )
fmt . Println ( sliceB )
//[22 2 3]
//[22 2 3]
1
2
3
4
5
6
7
sliceA := [] int { 1 , 2 , 3 }
sliceB := sliceA
sliceB [ 1 ] = 66
fmt . Println ( sliceA )
fmt . Println ( sliceB )
//[1 66 3]
//[1 66 3]
多维数组
多维数组的定义:var 数组变量名 [元素数量][元素数量]T
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//多维数组
var arry = [ 3 ][ 2 ] string {
{ "上海" , "北京" },
{ "杭州" , "广州" },
{ "深圳" , "成都" },
}
for _ , strings := range arry {
for _ , s := range strings {
fmt . Println ( s )
}
} //上海
北京
杭州
广州
深圳
成都
在多维数组的第一层数组可以用[…]的推导方式,编译器会自动判断有多少个一层数组。
第五章 切片
切片(Slice)是一个拥有相同类型元素的可变长度的序列。它是基于数组类型做的一层封装。
它非常灵活,支持自动扩容。
切片是一个引用类型 ,它的内部结构包含地址 、长度 和容量 。
声明切片类型的基本语法如下:
var name []T
切片定义如果不进行赋值的话值为nil
1
2
3
var sliceA [] int
fmt . Println ( sliceA )
fmt . Println ( sliceA == nil )
输出:
切片的遍历
和数组一样可以使用for 和for range循环
1
2
3
4
sliceA := [] int { 1 , 5 , 121 , 33 , 53 }
for _ , v := range sliceA {
fmt . Println ( v )
}
基于数组的切片
切片的底层就是一个数组,可以基于数组定义切片
1
2
3
4
5
6
arr := [ ... ] int { 22 , 52 , 6 , 78 , 92 }
sliceA := arr [ 1 :] //从数组元素索引1开始到最后一个元素
sliceB := arr [: 3 ] //从数组元素索引3不包括3到第一个元素
sliceC := arr [:] // 所有数组元素
fmt . Println ( sliceC , sliceB , sliceA )
// [22 52 6 78 92] [22 52 6] [52 6 78 92]
切片的长度和容量
切片的长度和数组一样表示元素的个数,可以用len()方法获取,切片的容量可以用cap()函数获取。
切片的容量:表示从第一个切片元素开始到底层数组最后一个元素的个数
1
2
3
4
arr := [ ... ] int { 22 , 52 , 6 , 78 , 92 }
sliceA := arr [: 2 ]
fmt . Printf ( "%d %d" , len ( sliceA ), cap ( sliceA )) // 切片sliceA为[22,52] 容量是从22开始到92一共5
// 2 5
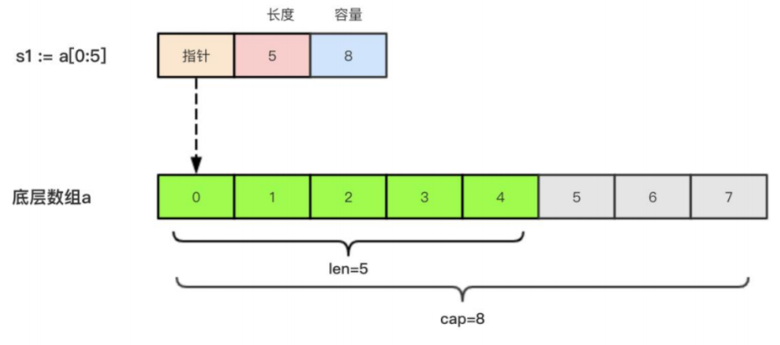
切片的本质
切片的本质就是对底层数组的封装,它包含了三个信息:底层数组的指针、切片的长度(len)
和切片的容量(cap)。
举个例子,现在有一个数组 a := [8]int{0, 1, 2, 3, 4, 5, 6, 7},切片 s1 := a[:5],相应示意图如下。
使用make()函数创建切片
通过 var variable []类型来创建的切片,它的长度和容量都是0,值是nil,不能通过下标的形式进行扩容。如果要动态的创建一个切片,可以使用内置函数make来创建。
语法:
1
var sliceA = make ([] T , size , cap )
1
2
3
4
5
6
sliceA := make ([] int , 5 , 5 ) //切片的长度是5,容量也是5
fmt . Printf ( "%v %v %v\n" , sliceA , len ( sliceA ), cap ( sliceA ))
sliceA [ 0 ] = 20
fmt . Printf ( "%v %v %v" , sliceA , len ( sliceA ), cap ( sliceA ))
//[0 0 0 0 0] 5 5
//[20 0 0 0 0] 5 5
切片是引用数据类型
切片通过赋值操作或是函数传参,传递的是一个切片的引用。
append()方法
通过var variable []Type 定义的切片不能通过下标扩容,但可以使用append()方法进行扩容
1
2
3
4
var sliceA [] int
sliceA = append ( sliceA , 10 )
fmt . Printf ( "%v %v %v" , sliceA , len ( sliceA ), cap ( sliceA ))
//[10] 1 1
append方法还可以合并多个切片
1
2
3
4
5
6
sliceA := [] int { 1 , 2 , 3 }
sliceB := [] int { 5 , 6 , 7 }
//把切片sliceB合并到切片A中
sliceA = append ( sliceA , sliceB ... )
fmt . Printf ( "值:%v 长度:%v 容量:%v" , sliceA , len ( sliceA ), cap ( sliceA ))
//值:[1 2 3 5 6 7] 长度:6 容量:6
利用append删除切片元素:golang没有提供删除切片元素的方法,利用append可以实现
1
2
3
4
5
sliceA := [] int { 33 , 66 , 22 , 33 , 77 , 55 } //底层有一个6个元素的数组
// 删除下标为3的元素
sliceA = append ( sliceA [: 3 ], sliceA [ 4 :] ... )
fmt . Printf ( "值:%v 长度:%v 容量:%v" , sliceA , len ( sliceA ), cap ( sliceA ))
// 值:[33 66 22 77 55] 长度:5 容量:6 容量还是6因为底层数组元素是6个
总结:删除切片索引为i的元素可以用下方法:
sliceA = append(sliceA[:i],aliceA[i+1:]…)
利用copy函数复制切片
由于切片是引用数据类型,赋值操作都会指向同一个内存地址,无论改变哪个切片都会影响另一个切片。copy函数可以解决这个问题。
Go 语言内建的 copy()函数可以迅速地将一个切片的数据复制到另外一个切片空间中,copy()
函数的使用格式如下
copy(destSlice, srcSlice []T)
1
2
3
4
5
6
7
8
sliceA := [] int { 2 , 5 , 6 , 8 , 9 }
sliceB := make ([] int , 5 , 8 )
copy ( sliceB , sliceA )
sliceB [ 0 ] = 333 // 现在修改sliceB的值不会影响silceA
fmt . Println ( sliceA )
fmt . Println ( sliceB )
// [2 5 6 8 9]
// [333 5 6 8 9]
利用copy函数删除切片中的某一元素不改变原切片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import "fmt"
func main () {
S := [] int { 1 , 2 , 3 , 4 , 5 , 6 }
ele := CopyDelEle ( S , 2 )
fmt . Println ( ele ) //[1 2 4 5 6]
fmt . Println ( S ) // [1 2 3 4 5 6]
}
func CopyDelEle ( slice [] int , index int ) [] int {
srcSliceA := slice // [1,2,3,4,5]
distSlice := make ([] int , index )
copy ( distSlice , srcSliceA [: index ])
distSlice = append ( distSlice , srcSliceA [ index + 1 :] ... )
return distSlice
}
sort.ints()方法可以对切片排序
第六章 map类型
在golang 中map类型是一种基于key-value的数据结构,map是引用数据类型,map是基于key来快速检索的,可以通过for range遍历。map中的数据是无序的。
map的定义
var 变量名[key-type]value-type
这样定义的map是一个nil,无法创建键值对,通常由make函数,(make函数可以创建slice,map,和channel)
通过通过下面两种方法创建:make()函数
1
2
3
userinfo := make ( map [ string ] string )
userinfo [ "username" ] = "张三"
fmt . Println ( userinfo )
或者在定义的时候直接初始化
1
2
3
4
5
6
7
userinfo := map [ string ] string {
"username" : "张三" ,
"age" : "20" ,
"gender" : "男" ,
}
fmt . Printf ( "%v %v" , userinfo , len ( userinfo ))
// map[age:20 gender:男 username:张三] 3
判断某一key是否存在
1
2
3
4
5
6
7
8
9
10
userinfo := map [ string ] string {
"username" : "张三" ,
"age" : "20" ,
"gender" : "female" ,
}
v , ok := userinfo [ "username" ] // v是username对应的value,如果有ok就是true
if ok {
fmt . Println ( v , ok )
}
// 张三 true
map的遍历
可以使用for range遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
userinfo := map [ string ] string {
"username" : "张三" ,
"age" : "20" ,
"gender" : "female" ,
}
v , ok := userinfo [ "username" ]
if ok {
fmt . Println ( v , ok )
}
for key , value := range userinfo {
fmt . Printf ( "%v:%v\n" , key , value )
}
//username:张三
//age:20
//gender:female
delete()方法删除键值对
delete(map,key)
map:代表要删除的map
key:代表要删除的键
1
2
3
4
5
6
7
8
userinfo := map [ string ] string {
"username" : "张三" ,
"age" : "20" ,
"gender" : "female" ,
}
delete ( userinfo , "age" )
fmt . Println ( userinfo )
// map[gender:female username:张三]
元素是map类型的切片
1
2
3
4
5
6
7
8
9
10
11
12
sliceA := [] map [ string ] string {
{
"username" : "张三" ,
"age" : "20" ,
},
{
"username" : "李四" ,
"age" : "30" ,
},
}
fmt . Println ( sliceA )
// [map[age:20 username:张三] map[age:30 username:李四]]
map的值是切片类型
1
2
3
4
5
mapA := make ( map [ string ] interface {})
mapA [ "username" ] = "张三"
mapA [ "hubby" ] = [] string { "篮球" , "足球" , "写代码" }
fmt . Println ( mapA )
// map[hubby:[篮球 足球 写代码] username:张三]
另一个定义方法:
1
2
3
4
5
6
mapA := map [ string ] interface {}{
"username" : "张三" ,
"hubby" : [] string { "篮球" , "足球" , "写代码" },
}
fmt . Println ( mapA )
// map[hubby:[篮球 足球 写代码] username:张三]
map练习
统计一个字符串中每个单词出现的次数
1
2
3
4
5
6
7
8
9
str := "how do you do"
strSlice := strings . Split ( str , " " )
mapA := make ( map [ string ] int )
for _ , value := range strSlice {
mapA [ value ] ++
}
fmt . Println ( mapA )
// map[do:2 how:1 you:1]
第七章 函数
函数是什么?是可以重复执行的代码块
Go 语言中支持:函数、匿名函数和闭包
函数定义用关键字func
函数的定义
1
2
3
4
func sum ( x , y int ) int {
sum := x + y
return sum
}
定义好函数后就可以调用了
函数的参数
参数简写 如果函数参数的类型一样,第一个参数的类型可以省略
可变参数
可变参数值函数的参数数量传入不固定,golang中可以在类型前用 “…”表示
1
2
3
4
5
6
7
8
9
10
11
func sum ( x int , y ... int ) int {
sum := x
for _ , v := range y {
sum += v
}
return sum
}
调用
total := sum ( 10 , 1 , 2 , 3 , 4 , 5 ) //第一个10赋值给x 1,,2,,3,4,5会以切片的形式赋值给y
fmt . Println ( total )
// 25
参数y是一个切片
函数的返回值
通过return关键字向外返回。如果有多个返回值必须用()包裹
返回值命名
函数定义时可以给返回值命名,并在函数体中直接使用这些变量,最后通过 return 关键字
返回
1
2
3
4
5
func calc ( x , y int ) ( sum , sub int ) {
sum = x + y
sub = x - y
return
}
变量作用域
全局变量:定义在函数体外的变量,在整个程序运行期间都有效。函数内部可以访问全局变量,
全局变量只能用var 或const来定义不能用:
局部变量:定义在函数内部或循环体的变量,函数外部无法访问。
函数类型
通过type关键字可以自定义一个函数类型
1
2
//函数类型,可以用type关键字定义一个函数类型
type calc func ( int , int ) int //定义了一个calc的函数类型
calc是类型名,这个类型的函数接受2个int类型数据,返回一个int类型数据
只要符合这个类型的函数都可以赋值给这个类型变量
函数类型变量
定义了函数类型后就可以初始化函数类型变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
package main
import "fmt"
//函数类型,可以用type关键字定义一个函数类型
type calc func ( int , int ) int //定义了一个calc的函数类型
func add ( x , y int ) int {
return x + y
}
func main () {
// 定义一个函数类型calc的变量
var c calc
c = add // 把符合calc类型的函数赋值给c
fmt . Println ( c ( 5 , 6 ))
}
函数作为参数
函数可以作为参数传递给另一个函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
package main
import "fmt"
//函数类型,可以用type关键字定义一个函数类型
type calc func ( int , int ) int //定义了一个calc的函数类型
func add ( x , y int ) int {
return x + y
}
func sub ( x , y int ) int {
return x - y
}
// cb是一个函数,类型是自定义函数类型calc 也就是func(int, int) int
func calculation ( x int , y int , cb calc ) int {
//调用传递的函数
return cb ( x , y )
}
func main () {
sum := calculation ( 10 , 20 , add ) //把函数add作为参数传递
fmt . Println ( sum )
}
函数当做返回值
函数不仅可以作为参数还可以作为返回值返回一个函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
func add ( x , y int ) int {
return x + y
}
func sub ( x , y int ) int {
return x - y
}
func calc ( str string ) func ( int , int ) int {
switch str {
case "+" :
return add
case "-" :
return sub
case "*" :
return func ( x , y int ) int { //返回一个匿名函数,如果在函数体内定义函数只能定义成匿名函数
return x * y
}
default :
return nil
}
}
func main () {
a := calc ( "+" )
fmt . Println ( a ( 5 , 9 )) //14
s := calc ( "-" )
fmt . Println ( s ( 6 , 3 )) //3
m := calc ( "*" )
fmt . Println ( m ( 5 , 6 )) //30
}
匿名函数
匿名函数就是没有定义函数名的函数,匿名函数由于没有变量名,所以不能通过函数名调用,匿名函数可以赋值一个变量或者加()立即执行。匿名函数主要用于回调函数和闭包。
1
2
3
4
5
6
7
8
9
10
11
func main () {
//匿名函数赋值给一个变量
fn := func ( x , y int ) int {
return x + y
}
fmt . Println ( fn ( 5 , 8 ))
// 匿名函数立即执行
func ( x , y int ) {
fmt . Println ( x + y )
}( 10 , 20 )
}
函数的递归
函数调用自己就是函数的递归调用
实现1-100相加
1
2
3
4
5
6
7
//递归实现1-100的和
func fn ( x int ) int {
if x == 0 {
return 0
}
return x + fn ( x - 1 ) //3+f(2) //3+2+fn(1) // 3+2+1 +fn(0)
}
实现5的阶乘
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
package main
import "fmt"
func main () {
a := fn2 ( 5 )
fmt . Println ( a ) //120
}
func fn2 ( x int ) int {
if x > 1 {
return x * fn2 ( x - 1 ) //5*fn(4) // 5*4*fn(3) //5*4*3*fn(2) //5*4*3*2*fn(1)
} else {
return 1
}
}
闭包
闭包可以理解成“定义在一个函数内部的函数“。在本质上,闭包是将函数内部和函数外部
连接起来的桥梁。或者说是函数和其引用环境的组合体使用闭包可以让外界访问函数内部的变量。
闭包内部的变量:常驻内存,不污染全局
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
package main
import "fmt"
func main () {
fn2 := fn ()
fmt . Println ( fn2 ( 10 )) // 输出20
fmt . Println ( fn2 ( 10 )) // 输出30 因为此时x=20+10
fmt . Println ( fn2 ( 10 )) // 输出40 因为此时x=30+10
}
func fn () func ( int ) int {
x := 10
return func ( y int ) int {
x += y
return x
}
}
变量 fn2 是一个函数并且它引用了内部作用域中的 x 变量,此时 fn2 就是一个闭包。 在 fn2的生命周期内,变量 x 也一直有效,闭包其实并不复杂,只要牢记闭包=函数+引用环境.
理解:闭包就是函数内部return出去的函数,这个函数在外部调用了函数内部的局部变量。
defer 语句
defer 让函数延迟执行,先被defer声明的语句后执行,最后被defer声明的语句最先执行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
package main
import "fmt"
func main () {
fmt . Println ( "开始" )
defer func () {
fmt . Println ( "1" )
}()
defer func () {
fmt . Println ( "2" )
}()
defer func () {
fmt . Println ( "3" )
}()
fmt . Println ( "结束" )
}
//开始
//结束
//3
//2
//1
由于 defer 语句延迟调用的特性,所以 defer 语句能非常方便的处理资源释放问题。比如:
资源清理、文件关闭、解锁及记录时间等
例子:
1
2
3
4
5
6
7
8
func f1 () int {
x := 5
defer func () {
x ++
}()
return x
}
//输出 为5
命名返回值的情况:
1
2
3
4
5
6
7
func f2 () ( x int ) { //x为命名返回值,可以在函数中使用x开始是0
defer func () {
x ++ //再执行 x++ x变为6 最后返回值为6
}()
return 5 // 先执行return 5 x为5
}
// 6
内置函数 panic和recover
panic用来抛出异常,recover用来捕获异常,让程序不崩溃
recover 只能用在defer语句中,因为只有先产生了异常,然后才会捕获
没有使用panic和recover的程序
1
2
3
4
5
6
7
8
9
package main
import "fmt"
func main () {
fmt . Println ( div ( 10 , 0 ))
fmt . Println ( "结束程序" )
}
func div ( x , y int ) int {
return x / y
}
panic: runtime error: integer divide by zero
goroutine 1 [running]:
main.div(…)
main.main()
D:/awesomeProject1/demo9/demo9.go:6 +0x12
exit status 2
PS D:\awesomeProject1\demo9> go run .\demo9.go
panic: runtime error: integer divide by zero
出现panic,导致程序崩溃。
使用panic和recover
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
func main () {
fmt . Println ( div ( 10 , 0 ))
fmt . Println ( "结束程序" )
}
func div ( x , y int ) int {
defer func () {
err := recover ()
if err != nil {
fmt . Println ( err )
}
}()
return x / y
}
// runtime error: integer divide by zero
//0
//结束程序
程序没有奔溃。
第八章 time包
获取当前时间对象
获取当前时间对象
1
2
3
4
5
6
7
8
9
10
11
12
now := time . Now ()
fmt . Println ( now )
// 获取年月日时分秒方法
year := now . Year ()
month := now . Month ()
day := now . Day ()
hour := now . Hour ()
minute := now . Minute ()
second := now . Second ()
//时间格式化输出字符串 方式一
time := fmt . Sprintf ( "%d-%02d-%02d %02d:%02d:%02d" , year , month , day , hour , minute , second )
fmt . Println ( time )
输出:
2024-04-13 20:43:46.2061317 +0800 CST m=+0.008780301
2024-04-13 20:49:38
格式化时间输出方式二
1
2
3
now := time . Now ()
dateStr := now . Format ( "2006-01-02 15:03:04" ) //固定写法
fmt . Println ( dateStr )
获取当前时间戳
1
2
3
4
5
6
7
8
9
10
11
timeStampSecond := time . Now (). Unix () //秒时间戳
fmt . Println ( timeStampSecond )
//毫秒时间错
timeStampMill := time . Now (). UnixMilli ()
fmt . Println ( timeStampMill )
//微秒时间戳
timeStampMicro := time . Now (). UnixMicro ()
fmt . Println ( timeStampMicro )
//纳秒时间戳
timeStampNano := time . Now (). UnixNano ()
fmt . Println ( timeStampNano )
时间戳转为时间对象
1
2
3
4
//将毫秒时间戳转为时间对象
var timeStamp int64 = 1713013113882
timeObj := time . UnixMilli ( timeStamp )
fmt . Println ( timeObj )
将字符串转为时间对象
1
2
3
4
var str = "2024-04-13"
var template = "2006-01-02"
timeObj , _ := time . ParseInLocation ( template , str , time . Local )
fmt . Println ( timeObj )
输出:
2024-04-13 00:00:00 +0800 CST
第九章 指针,make和new 方法
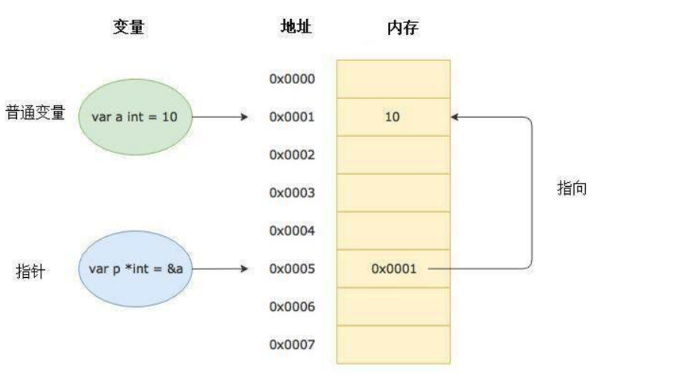
什么是指针?
变量是用来存储数据的,变量的本质是用一个好记忆的名字来存储内存地址,实际上变量的值是存在具体的内存地址中的。在计算机底层这个变量就对应一个内存地址指向这个值。
指针也是一种变量,它存储的是另一个变量的内存地址。
普通变量a=10,a变量实际指向内存地址0X0001,0X0001地址上存储的是值10,p变量是指针,存储的是a变量指向的内存地址0x0001。
Go 语言中的指针操作非常简单,我们只需要记住两个符号 :&(取地址)和 *(根据地址
取值)
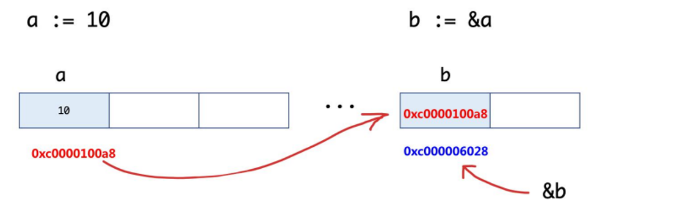
取变量地址&
定义一个普通变量后如何取到这个变量对应的内存地址呢?
通过**&符号。**
1
2
3
4
5
6
7
var a = 10
var b * int
b = & a // 取变量a对应的内存地址赋值给指针b
fmt . Println ( & a ) // 打印a的内存地址
fmt . Printf ( "%v " , b ) // 打印指针b的值
//0xc0000ba058
//0xc0000ba058
指针变量在内存中也有自己的地址用&b可以取到。
根据地址取值*b
普通变量直接通过变量可以取到值,指针变量用*变量名 可以直接取到变量的值。
如上面的a=10,b=&a *b就是根据地址取值为10.
1
2
3
4
5
6
7
var a = 10
var p * int
p = & a
fmt . Println ( & a )
fmt . Printf ( "%v " , * p )
//0xc00001a098
//10
总结: 取地址操作符&和取值操作符*是一对互补操作符,&取出地址,*根据地址取出地址
指向的值。
指针传值
在函数传递参数时候,由于基本数据类型和数组都是值类型,在传参的时候是拷贝一份传递,在函数中并不会修改原来的值。当传递的参数是一个自定义类型(如struct)时,通常推荐使用指针来传递,这样可以减少内存的复制,提高效率。但是如果你想要保持原始值不变,那么可以选择传递值。
通过向函数传递指针类型的变量,把值类型的地址传给函数,那么在函数内部就可以通过内存地址直接修改这值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
package main
import "fmt"
func main () {
a := 10
fn1 ( a ) //打印10
fmt . Println ( a )
fn2 ( & a ) //方法fn2的参数是变量a的地址
fmt . Println ( a ) //打印30
}
func fn1 ( x int ) {
x += 1
}
func fn2 ( p * int ) {
* p = 30 //通过*p直接修改a变量内存中的值
}
例子2 变量交换值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
package main
import "fmt"
func main () {
a := 100
b := 200
swap ( & a , & b )
fmt . Println ( a , b )
}
func swap ( x , y * int ) {
var temp int
temp = * x //通过地址取值取到a的值,赋值给temp
* x = * y // 将*y取到的值b 赋值给a
* y = temp // temp赋值给 b
}
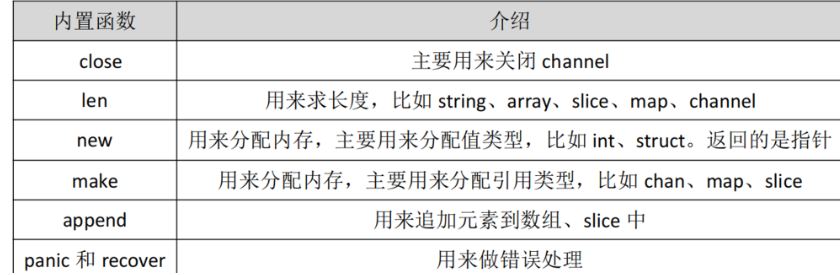
make 函数和new 函数
在 Go 语言中对于引用类型的变量,我们在使用
的时候不仅要声明它,还要为它分配内存空间,否则我们的值就没办法存储。而对于值类型
的声明不需要分配内存空间,是因为它们在声明的时候已经默认分配好了内存空间。要分配
内存,就引出来今天的 new 和 make。 Go 语言中 new 和 make 是内建的两个函数,主要用
来分配内存。
make函数用于给引用类型slice,map,channel分配内存地址
new函数:使用 new 函数得到的是一个类型的指针,并且该指针对应的值为该类型的零值。
每种基本类型都有对应的指针类型*int,*string,*bool…
3、new 与 make 的区别
二者都是用来做内存分配的。
make 只用于 slice、map 以及 channel 的初始化,返回的还是这三个引用类型本身
而 new 用于值类型的内存分配,并且内存对应的值为类型零值,返回的是指向类型的指
针
第十章 结构体
golang中数组可以存储一组相同数据类型的数据,比较单一。
Golang 提供了一种
自定义数据类型,可以封装多个基本数据类型,这种数据类型叫结构体,英文名称 struct。
也就是我们可以通过 struct 来定义自己的类型了。
golang的结构体和其他语言的类有点类似。
type关键字
type关键字可以定义自定义类型和自定义类型的别名。
1
2
3
4
5
6
7
8
9
10
//type关键字可以定义自定义类型和类型别名
type myInt int // 自定义类型
type myFloat = float64 // 类型别名 myFloat是float64的别名
var a myInt = 12
var b myFloat = 12.21
fmt . Printf ( "%v %T \n" , a , a )
fmt . Printf ( "%v %T \n" , b , b )
12 main . myInt
12.21 float64 //别名打印的还是原来的类型
结构体的初始化
结构体是值类型,可以像初始化基本数据类型一样使用var关键字,golang在初始化的时候就会给分配内存空间。
方法一:var 初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
package main
import "fmt"
type Person struct {
Name string
Age int
Gender string
}
func main () {
//实例化结构体
var p Person
p . Gender = "男"
p . Name = "张三"
p . Age = 28
fmt . Printf ( "%#v 类型是%T" , p , p )
}
//main.Person{Name:"张三", Age:28, Gender:"男"} 类型是main.Person
方法二:利用new关键字
new关键字可以给值类型分配内存空间返回的是该类型的指针变量
1
2
3
4
5
6
p2 := new ( Person ) // 通过new关键字得到的p2是一个结构体指针,存储的Person结构体的地址
p2 . Gender = "女"
p2 . Name = "小花"
p2 . Age = 30
fmt . Printf ( "%#v %T" , p2 , p2 )
// &main.Person{Name:"小花", Age:30, Gender:"女"} *main.Person
注意 :在 Golang 中支持对结构体指针 直接使用.来访问结构体的成员。p2.name = “张三” 其
实在底层是(*p2).name = “张三”
方法三:和new关键字类似使用&符号取结构体的地址
1
2
3
4
5
6
p3 := & Person {}
p3 . Name = "李四"
p3 . Age = 30
p3 . Gender = "男"
fmt . Printf ( "%#v %T" , p3 , p3 )
//&main.Person{Name:"李四", Age:30, Gender:"男"} *main.Person
方法四:
1
2
3
4
5
6
7
p4 := Person { // 初始化的时候填充字段
Name : "王五" ,
Age : 40 ,
Gender : "男" ,
}
fmt . Printf ( "%#v %T" , p4 , p4 )
// main.Person{Name:"王五", Age:40, Gender:"男"} main.Person
结构体方法和接受者
在 go 语言中,没有类的概念但是可以给类型(结构体,自定义类型)定义方法。所谓方法
就是定义了接收者的函数。接收者的概念就类似于其他语言中的 this 或者 self。
定义格式:
func (接收者变量 接收者类型) 方法名(参数列表) (返回参数) {
函数体
}
接受者变量 :类似于this,相当于结构体实例化用,哪个实例后调用这个方法,那么这个实例会拷贝一个传给接受者变量,在方法中就可以使用这个实例。因为结构体是值类型,所以在函数体内修改这个实例的拷贝并不会改变实例本身。官方建议:变量名为结构体的第一个字母的小写。
例如,Person 类型的接收者变量应该命名为 p,
Connector 类型的接收者变量应该命名为 c 等
接受者类型 :定义的结构体,可以是指针类型和非指针类型,如果是指针类型那么传递的是实例的地址,在函数中通过地址可以修改实例本身。
例子:接受者为非指针类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
//package main
import "fmt"
type Person struct {
Name string
Age int
Gender string
}
//定义结构体方法
func ( p Person ) GetInfo () { //这里相当于是哪个实例调用方法会把实例拷贝赋值给p
p . Age = 20 //但因为结构体是值类型所以并不会改变实例本身的值
p . Name = "小花"
p . Gender = "女"
fmt . Printf ( "%#v %T\n " , p , p )
}
func main () {
//结构体方法和接受者
p := Person {
Name : "张三" ,
Age : 30 ,
Gender : "男" ,
}
p . GetInfo ()
fmt . Printf ( "%#v %T\n" , p , p )
}
//main.Person{Name:"小花", Age:20, Gender:"女"} main.Person
//main.Person{Name:"张三", Age:30, Gender:"男"} main.Person
例子2:接受者类型是结构体指针
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
package main
import "fmt"
type Person struct {
Name string
Age int
Gender string
}
//定义结构体方法
func ( p * Person ) GetInfo () { //接受者类型是结构体指针,p是结构体实例的地址所以在函数中修改
//会改变实例本身的值
p . Age = 20
p . Name = "小花"
p . Gender = "女"
fmt . Printf ( "%#v %T\n " , p , p )
}
func main () {
//结构体方法和接受者
p := Person {
Name : "张三" ,
Age : 30 ,
Gender : "男" ,
}
p . GetInfo ()
fmt . Printf ( "%#v %T\n" , p , p )
}
// &main.Person{Name:"小花", Age:20, Gender:"女"} *main.Person
// main.Person{Name:"小花", Age:20, Gender:"女"} main.Person
嵌套结构体
在一个结构体中嵌套另一个结构体或结构体指针
结构体的继承
golang中在结构体中嵌套结构体可以实现继承
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
package main
import "fmt"
type Person struct {
Name string
Age int
Gender string
}
type Teacher struct {
Class string
Person //在教师结构体中嵌套人的结构体,那么教师结构体就会拥有Person结构体的
//属性和方法
}
func ( p Person ) Run () {
fmt . Println ( p . Name + "会奔跑" )
}
func ( t Teacher ) Teach () {
fmt . Println ( t . Name + "教书" )
}
//定义结构体方法
func ( p * Person ) GetInfo () {
fmt . Printf ( "%#v %T\n " , p , p )
}
func main () {
t := Teacher {
Class : "科学" ,
Person : Person {
Name : "李老师" ,
Age : 25 ,
Gender : "女" ,
},
}
t . Teach ()
t . Run ()
t . GetInfo ()
}
//李老师教书
//李老师会奔跑
//&main.Person{Name:"李老师", Age:25, Gender:"女"} *main.Person
结构体与JSON序列化
json是一种轻量级的数据交换格式,在api接口传送的数据格式基本都是json格式。
在go中结构体和json数据如何转换呢?这里用到"encoding/json"包中的json.Marshal()方法,此方法可以把结构体序列化为json格式.
1
2
3
4
5
6
7
8
9
10
11
12
13
func main () {
user := & User {
Username : "张三" ,
Password : "123456" ,
Gender : "男" ,
Mobile : "18989898989" ,
}
jsonStrByte , err := json . Marshal ( user ) // 这里序列化为byte类型的切片,byte就是uint8类型。输出的是ascii码的值十进制数,一个英文字母占用8位,0-255。
if err != nil {
fmt . Println ( err )
}
fmt . Println ( string ( jsonStrByte ))
}
输出:
1
{"Username":"张三","Password":"123456","Gender":"男","Mobile":"18989898989"}
json字符串反序列化成结构体
用到json.Unmarshal()方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
type User struct {
Username string
Password string
Gender string
Mobile string
}
func main () {
var user User
jsonStr := `{"Username":"张三","Password":"123456","Gender":"男","Mobile":"18989898989"}`
err := json . Unmarshal ([] byte ( jsonStr ), & user )
if err != nil {
fmt . Println ( err )
}
fmt . Println ( user )
}
结构体tag标签
结构体中的字段除了名字和类型外,还可以有一个可选的标签tag,它是一个附属于字段的字符串,可以使文档或是其他信息。标签的内容只有在reflect包中能够读取。它可以让程序运行的时候通过反射机制读取到。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
type User struct {
Username string "Username information"
Password int "user password information"
Gender string "user gender information"
Mobile string "user mobile information"
}
func main () {
user := User {
Username : "张三" ,
Password : 123456 ,
Gender : "男" ,
Mobile : "15956569591" ,
}
userType := reflect . TypeOf ( user ) //返回变量user的类型
field := userType . Field ( 1 ) // 如果userType是结构体,就可以用Fied()方法索引字段,0为Username,1为Password
fmt . Println ( userType )
fmt . Printf ( "%#v\n" , field )
fmt . Printf ( "%v" , field . Tag )
}
输出
1
2
3
main.User
reflect.StructField{Name:"Password", PkgPath:"", Type:(*reflect.rtype)(0x4ad8c0), Tag:"user password information", Offset:0x10, Index:[]int{1}, Anonymous:false}
user password information
json标签,序列化时候会将json:age 作为键名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
type User struct {
Username string "Username information"
Password int "user password information"
Gender string "user gender information"
Mobile string "user mobile information"
Age int `json:"age"`
}
func main () {
user := User {
Username : "张三" ,
Password : 123456 ,
Gender : "男" ,
Mobile : "15956569591" ,
Age : 25 ,
}
strByte , _ := json . Marshal ( user )
fmt . Println ( string ( strByte ))
fmt . Printf ( "%#v" , reflect . TypeOf ( user ). Field ( 4 ))
}
输出
1
2
{"Username":"张三","Password":123456,"Gender":"男","Mobile":"15956569591","age":25}
reflect.StructField{Name:"Age", PkgPath:"", Type:(*reflect.rtype)(0x4267e0), Tag:"json:\"age\"", Offset:0x38, Index:[]int{4}, Anonymous:false}
第十章 接口(interface)
在golang中接口是一种抽象数据类型,它定义了对象的行为规范(方法),只定义不实现,具体的由具体的对象实现。
通俗的讲接口就一个标准,它是对一个对象的行为和规范进行约定,约定实现接口的对象必
须得按照接口的规范。
Golang 中每个接口由数个方法组成,接口的定义格式如下:
type 接口名 interface {
方法名 1( 参数列表 1 ) 返回值列表 1
方法名 2( 参数列表 2 ) 返回值列表 2
…
}
其中:
接口名 :使用 type 将接口定义为自定义的类型名。Go 语言的接口在命名时,一般会在
单词后面添加 er,如有写操作的接口叫 Writer,有字符串功能的接口叫 Stringer 等。接
口名最好要能突出该接口的类型含义。
方法名 :当方法名首字母是大写且这个接口类型名首字母也是大写时,这个方法可以被
接口所在的包(
package)之外的代码访问。
参数列表、返回值列表 :参数列表和返回值列表中的参数变量名可以省略
实例:定义一个Phone接口,让NokiaPhone结构体实现Phone接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
package main
import "fmt"
//接口也是一种数据类型,其他类型只要实现了接口的方法就是实现了这个接口
//定义 Phone接口,接口有call方法
type Phone interface {
call ()
}
type NokiaPhone struct {
Name string
}
func ( n NokiaPhone ) call () {
fmt . Println ( n . Name + "手机" )
}
func main () {
var phone Phone
phone = new ( NokiaPhone )
phone . call ()
}
空接口
没有定义任何方法的接口就是空接口,空接口也是一种数据类型可以写成interface{},
空接口表示没有任何约束,任何数据类型都可以实现空接口,也就是说空接口类型可以接收任何类型数据。
例子:基本数据类型实现空接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
package main
import "fmt"
//空接口类型,空接口也是一种类型,任何类型的变量都可以实现空接口,也就是说空接口可以接受任何变量类型
type Phone interface {
}
func main () {
var p Phone
var num int
num = 10
p = num //int实现空接口
fmt . Println ( p )
str := "string类型实现空接口"
p = str
fmt . Println ( str )
boolean := true
p = boolean // bool类型实现空接口
fmt . Println ( p )
f := 3.1415
p = f //folat类型实现空接口
fmt . Println ( f )
}
空接口作为函数的参数
空接口作为函数的参数可以接受任何数据类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
package main
import "fmt"
func main () {
b := Print ( "接受一个string类型" )
fmt . Println ( b )
c := Print ( 5 ) // 这里相当于 a=5 int实现空接口,因为 a interface{}
fmt . Println ( c )
d := 10
//fmt.Println(c + d) //如果返回的是空接口类型必须用接口断言后才能和整数相加
v , ok := c .( int )
if ok {
fmt . Println ( v + d )
}
}
//定义一个方法接受任意类型数据并返回
func Print ( a interface {}) interface {} {
return a
}
map类型的值实现空接口
使用空接口实现可以保存任意值的字典。
1
2
3
4
5
6
7
m := make ( map [ string ] interface {})
m [ "username" ] = "张三"
m [ "age" ] = 20
m [ "gender" ] = "男"
m [ "married" ] = true
fmt . Printf ( "%v %T" , m , m )
// map[age:20 gender:男 married:true username:张三] map[string]interface {}
切片实现空接口
切片实现空接口,切片元素可以是任意类型值
1
2
3
4
5
//切片实现空接口,数据类型可以是任意类型
sliceA := [] interface {}{ 1 , "切片实现空接口" , true , 3.1515 , map [ string ] interface {}{ "username" : "张三" , "age" : 20 }}
fmt . Println ( sliceA )
//map[age:20 gender:男 married:true username:张三] map[string]interface {}[1 切片实现空接口 true 3.1515 map[age:20 username:
张三 ]]
类型断言
一个接口的值(简称接口值)是由一个具体类型和具体类型的值两部分组成的。这两部分分
别称为接口的动态类型和动态值。
如果我们想要判断空接口中值的类型,那么这个时候就可以使用类型断言,其语法格式
x.(T)
其中:
x : 表示类型为 interface{}的变量
T : 表示断言 x 可能是的类型。
该语法返回两个参数,第一个参数是 x 转化为 T 类型后的变量,第二个值是一个布尔值,若为 true 则表示断言成功,为 false 则表示断言失败。
注意 :类型.(type)只能结合 switch 语句使用
**关于接口需要注意的是:**只有当有两个或两个以上的具体类型必须以相同的方式进行处理时
才需要定义接口。不要为了接口而写接口,那样只会增加不必要的抽象,导致不必要的运行
时损耗。
结构体值接受者和指针接受者的区别
值接受者:如果结构体方法中的接受者是值类型,那么实例化后的结构体值类型和指针类型都可以赋值给接口变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
package main
import "fmt"
type Phone interface {
call ()
}
type NokiaPhone struct {
Name string
}
//实现接口的方法,并且方法为值接受者,那么实例化结构体的值类型和指针类型都可以赋值给接口变量
func ( n NokiaPhone ) call () {
fmt . Println ( n . Name + "打电话" )
}
func main () {
// 实例化接口变量
var p Phone
//nokiaPhone 实例实现接口,值类型赋值给接口变量
nokiaPhone := NokiaPhone { Name : "诺基亚" }
p = nokiaPhone
p . call ()
nokiaPhone2 := & NokiaPhone { Name : "诺基亚1210" }
p = nokiaPhone2
p . call ()
}
指针接受者:
如果结构体方法是指针接受者,那么实例化结构体时候只能实例化成结构体指针类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
package main
import "fmt"
type Phone interface {
call ()
}
type NokiaPhone struct {
Name string
}
//实现接口的方法,并且方法是结构体指针
func ( n * NokiaPhone ) call () {
fmt . Println ( n . Name + "打电话" )
n . Name = "方法接受者是指针类型,可以修改实例的值"
}
func main () {
// 实例化接口变量
var p Phone
//由于结构体方法是指针接受者所以只能把结构体指针赋值给接口变量,错误如下
//nokiaPhone := NokiaPhone{Name: "诺基亚"}
//p = nokiaPhone
//p.call()
nokiaPhone2 := & NokiaPhone { Name : "诺基亚1210" }
p = nokiaPhone2
p . call () //修改了结构体实例的值
fmt . Println ( * nokiaPhone2 )
}
一个结构体实现多个接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
package main
import "fmt"
type Ainterface interface {
GetInfo () string
}
type Binterface interface {
SetInfo ( string )
}
type Person struct {
Name string
}
func ( p Person ) GetInfo () string {
return p . Name
}
func ( p Person ) SetInfo ( name string ) {
p . Name = name
}
func main () {
var a Ainterface
var b Binterface
var p = Person {
Name : "李四" ,
}
a = p
b = p
fmt . Println ( a . GetInfo ())
b . SetInfo ( "王五" ) // 这里方法并没有改变p结构体的值,因为结构体是值类型,传参是拷贝,不会改变原值,如果要
//改变原值,那么方法应该改为指针接受者
fmt . Println ( a . GetInfo ())
fmt . Println ( p )
}
//李四
//李四
//{李四}
修改结构体的方法是指针接受者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
package main
import "fmt"
type Ainterface interface {
GetInfo () string
}
type Binterface interface {
SetInfo ( string )
}
type Person struct {
Name string
}
func ( p Person ) GetInfo () string {
return p . Name
}
//定义方法为指针接受者
func ( p * Person ) SetInfo ( name string ) {
p . Name = name
}
func main () {
var a Ainterface
var b Binterface
//方法是指针接受者,实例化结构体必须是结构体指针
var p = & Person {
Name : "李四" ,
}
a = p
b = p
fmt . Println ( a . GetInfo ())
b . SetInfo ( "王五" ) // 由于方法是指着接受者,所以会改变原值
fmt . Println ( a . GetInfo ())
fmt . Println ( p )
}
//李四
//王五
//&{王五}
嵌套接口
接口与接口间可以通过嵌套创造出新的接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
package main
import "fmt"
type SayInterface interface {
say ()
}
type MoveInterface interface {
move ()
}
// 接口嵌套
type Animal interface {
SayInterface
MoveInterface
}
type Cat struct {
name string
}
func ( c Cat ) say () {
fmt . Println ( "喵喵喵" )
}
func ( c Cat ) move () {
fmt . Println ( "猫会动" )
}
func main () {
var x Animal
x = Cat { name : "花花" }
x . move ()
x . say ()
}
第十一章 go中的并发和并行
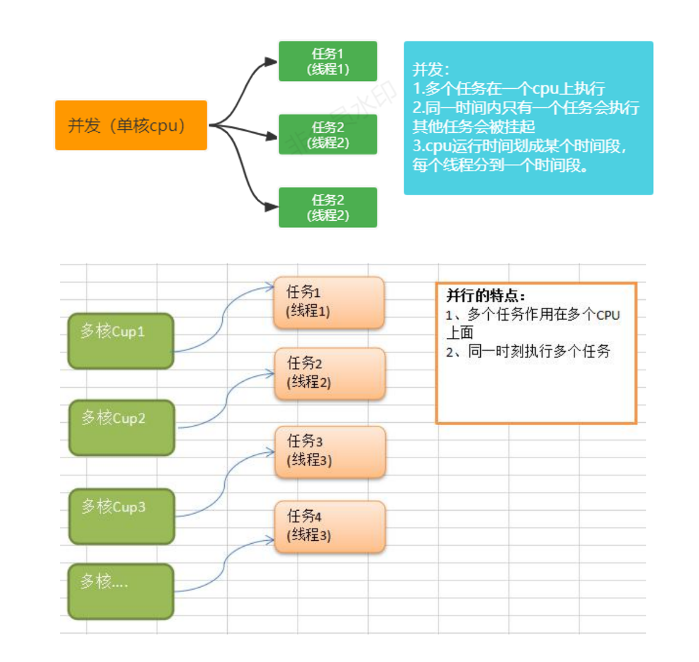
并发
当有多个线程在操作时,如果系统只有一个CPU,则它根本不可能真正同时进行一个以上的线程,它只能把CPU运行时间划分成若干个时间段,再将时间 段分配给各个线程执行,在一个时间段的线程代码运行时,其它线程处于挂起状。.这种方式我们称之为并发(Concurrent)
并行:
当系统有一个以上CPU时,则线程的操作有可能非并发。当一个CPU执行一个线程时,另一个CPU可以执行另一个线程,两个线程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)
区别:
并发和并行是即相似又有区别的两个概念,并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔内发生。在多道程序 环境下,并发性 是指在一段时间内宏观上有多个程序在同时运行,但在单处理机系统 中,每一时刻却仅能有一道程序执行,故微观上这些程序只能是分时地交替执行。倘若在计算机系统 中有多个处理机 ,则这些可以并发执行的程序便可被分配到多个处理机上,实现并行执行 ,即利用每个处理机来处理一个可并发执行的程序,这样,多个程序便可以同时执行
通俗的讲 多线程程序在单核 CPU 上面运行就是并发 ,多线程程序在多核 Cpu 上运行就是并
**行,**如果线程数大于 CPU 核数,则多线程程序在多个 CPU 上面运行既有并行又有并发
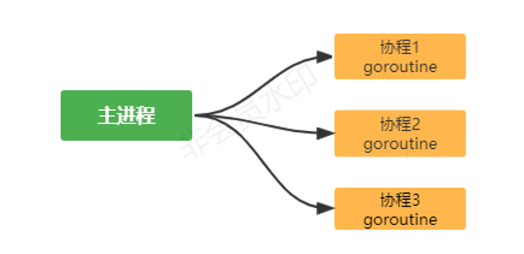
Golang 中的协程(goroutine)以及主线程 golang 中的主线程: (可以理解为线程/也可以理解为进程),在一个 Golang 程序的主线程
上可以起多个协程 。Golang 中多协程 可以实现并行或者并发。
**协程:**可以理解为用户级线程,这是对内核透明的,也就是系统并不知道有协程的存在,是
完全由用户自己的程序进行调度的。Golang 的一大特色就是从语言层面原生支持协程,在
函数或者方法前面加 go 关键字就可创建一个协程。可以说 Golang 中的协程就是
goroutine
golang中开启一个goroutine只需要2k的内存,java开启一个进程要2M内存
goroutine的使用和sync.waitgroup
为什么要使用sync.waitgroup,在golang中如果在主进程中开启其他goroutine,主进程并不会等待协程完成再退出,那么问题就是协程还没有执行完成,程序就退出了。
例子
1
2
3
4
5
6
7
8
9
10
11
12
package main
import "fmt"
func main () {
go test ()
fmt . Println ( "主进程退出" )
}
func test () {
for i := 0 ; i < 10 ; i ++ {
fmt . Println ( "协程打印的" , i )
}
}
//主进程退出
发现 并没有打印出协程中执行的程序。因为主进程已经结束了,可以在主进程中加句代码time.Sleep(time.Second) 等待1秒,但这个方法并不好。
使用sync.waitgroup实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
package main
import (
"fmt"
"sync"
)
var wg sync . WaitGroup
func main () {
wg . Add ( 1 ) //在协程执行前让wg 计数+1
go test ()
wg . Wait () //让主进程等待,看计数是否是0了 ,如果不是0会等待变成0后再执行主进程
fmt . Println ( "主进程退出" )
}
func test () {
for i := 0 ; i < 10 ; i ++ {
fmt . Println ( "协程打印的" , i )
}
wg . Done () //表示方法执行完成 会将wg计数-1
}
//协程打印的 0
协程打印的 1
协程打印的 2
协程打印的 3
协程打印的 4
协程打印的 5
协程打印的 6
协程打印的 7
协程打印的 8
协程打印的 9
主进程退出
设置 Golang 并行运行的时候占用的 cup 数量
Go 运行时的调度器使用 GOMAXPROCS 参数来确定需要使用多少个 OS 线程来同时执行 Go
代码。默认值是机器上的 CPU 核心数。例如在一个 8 核心的机器上,调度器会把 Go 代码同
时调度到 8 个 OS 线程上。
Go 语言中可以通过 runtime.GOMAXPROCS()函数设置当前程序并发时占用的 CPU 逻辑核心
数。
Go1.5 版本之前,默认使用的是单核心执行。Go1.5 版本之后,默认使用全部的 CPU 逻辑核
心数
1
2
3
4
5
6
7
8
9
10
11
12
package main
import (
"fmt"
"runtime"
)
func main () {
cpuNum := runtime . NumCPU ()
fmt . Println ( cpuNum )
}
// 8 个核心
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
package main
import (
"fmt"
"runtime"
"sync"
)
var wg sync . WaitGroup
func main () {
wg . Add ( 1 )
go test ()
cpuNum := runtime . NumCPU () //获取cpu个数
runtime . GOMAXPROCS ( 7 ) //设置最大进程数
cpuNum2 := runtime . NumGoroutine ()
fmt . Println ( cpuNum , cpuNum2 )
wg . Wait ()
}
func test () {
defer wg . Done ()
fmt . Println ( "开启一个协程" )
}
//8 2
//开启一个协程
统计0-100中的素数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
package main
import "fmt"
func main() {
//统计1-100中所有素数
for num := 2; num < 100; num++ {
var flag = true
for i := 2; i < i; i++ {
if num%i == 0 {
flag = false
break
}
}
if flag {
fmt.Println( num, "是素数" )
}
}
}
如果统计的是0-520000之间的素数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
package main
import (
"fmt"
"time"
)
func main() {
//统计1-100中所有素数
start := time.Now() .Unix()
fmt.Println( start)
for num := 2; num < 120000; num++ {
var flag = true
for i := 2; i < i; i++ {
if num%i == 0 {
flag = false
break
}
}
if flag {
//fmt.Println( num, "是素数" )
}
}
end := time.Now() .Unix()
fmt.Println( end)
fmt.Println( "程序运行了" , end-start, "秒" )
}
程序运行了 15 秒
相当于一个人在统计,现在实现并发4个人一起统计,开启4个协程
第一个协程统计:1-30000
第二个协程统计:30001-60000
第三个协程统计:60001:-90000
第四个协程统计:90001-120000
看看有什么效果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
package main
import (
"fmt"
"sync"
"time"
)
func test( n int) {
for num := ( n - 1) * 30000; num < n*30000; num++ {
var flag = true
for i := 2; i < i; i++ {
if num%i == 0 {
flag = false
break
}
}
if flag {
//fmt.Println( num, "是素数" )
}
}
wg.Done()
}
var wg sync.WaitGroup
func main() {
//统计1-100中所有素数
start := time.Now() .Unix()
for i := 1; i <= 4; i++ {
wg.Add( 1)
go test( i)
}
wg.Wait()
end := time.Now() .Unix()
fmt.Println( "程序运行了" , end-start, "秒" )
}
channel 管道
一 创建管道
1
chan1 := make ( chan int , 10 ) //创建一个容量是10的管道
//创建一个能存储 10 个 int 类型数据的管道
ch1 := make(chan int, 10)
//创建一个能存储 4 个 bool 类型数据的管道
ch2 := make(chan bool, 4)
//创建一个能存储 3 个[]int 切片类型数据的管道
ch3 := make(chan []int, 3)
二 channel 操作
管道有发送(send)、接收(receive)和关闭(close)三种操作。
1
chan1 <- 1 //将数据1 发送到管道
1
2
x := <- ch // 从 ch 中接收值并赋值给变量 x
<- ch // 从 ch 中接收值,忽略结果
关于关闭管道需要注意的事情是,只有在通知接收方 goroutine 所有的数据都发送完毕的时
候才需要关闭管道。管道是可以被垃圾回收机制回收的,它和关闭文件是不一样的,在结束
操作之后关闭文件是必须要做的,但关闭管道不是必须的
管道 阻塞
管道阻塞:如果管道定义时候没有指定容量,管道是阻塞的,向管道写入数据会报deadlock,同样,如果管道数据读取完毕了还在读取也会阻塞,报deadlock
用for range 循环遍历管道,管道必须是关闭的,for range会自动退出。
原因是:for range是阻塞式读取channel,只有channel close之后才会结束,否则会一直读取,通道里没有值了,还继续读取就会阻塞,程序就会报死锁
例子:goroutine 结合 channel 实现统计 1-120000 的数字中那些是素数?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
package main
import (
"fmt"
"sync"
)
//把需要统计的数字放入num chan
func putNum ( num chan int ) {
for i := 2 ; i < 100 ; i ++ {
num <- i
}
close ( num )
wg . Done ()
}
// 统计channel中的数字是否是素数
func isPrime ( num , primeNum chan int , exitChan chan bool ) {
for a := range num {
var flag = true
for i := 2 ; i < a ; i ++ {
if a % i == 0 {
flag = false
break
}
}
if flag {
primeNum <- a
}
}
exitChan <- true
wg . Done ()
}
var wg sync . WaitGroup
func main () {
var num = make ( chan int , 1000 )
var primeNum = make ( chan int , 50000 )
var exitChan = make ( chan bool , 16 )
// 把2-100的所有数字放入channel
wg . Add ( 1 )
go putNum ( num )
//开启协程统计管道中的数是否是素数
for i := 0 ; i < 16 ; i ++ {
wg . Add ( 1 )
go isPrime ( num , primeNum , exitChan )
}
//从管道中取出16个数据,取出完毕后关闭管道
go func () {
for i := 0 ; i < 16 ; i ++ {
<- exitChan
}
close ( primeNum )
}()
wg . Wait ()
for prime := range primeNum {
fmt . Println ( prime )
}
}
多个协程操作一个channel
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
package main
import (
"fmt"
"sync"
)
var wg sync . WaitGroup
func main () {
chan1 := make ( chan int , 10 )
for i := 0 ; i < 10 ; i ++ {
chan1 <- i
}
close ( chan1 )
for i := 0 ; i < 3 ; i ++ {
wg . Add ( 1 )
go func () {
for v := range chan1 {
fmt . Println ( v )
}
wg . Done ()
}()
}
wg . Wait ()
}
0
3
4
5
6
8
9
1
2
https://www.notion.so
理解为for range是阻塞式读取channel,当一个协程在读取for range 一个channel时候,另一个协程for range 只能读取channel剩下的数据,(不知道理解是否正确)
单向管道
1
2
chan1 := make ( chan <- int , 10 ) //这个是只能写的管道
chan2 := make ( <- chan int , 10 ) // 只能读的管道
the way to go